 In contrast to some personal feelings on LODLAM 2013 described in Part I, a rather formal oral presentation to my institution has been presented and shared here. This report (Part II) is written as a supplement to the presentation and takes into some discussion notes with my colleagues for a more comprehensive report.
In contrast to some personal feelings on LODLAM 2013 described in Part I, a rather formal oral presentation to my institution has been presented and shared here. This report (Part II) is written as a supplement to the presentation and takes into some discussion notes with my colleagues for a more comprehensive report.
An overview of the LODLAM 2013 agenda reflects current status of the LAM progress in LOD trends. The two day program was consist of 43 sessions in total and conveyed 7 emerging issues. Together with the observation which indicates the most frequent semantic web activities within the library domain are data integration, semantic search and semantic annotation, thus, I selected three cases to share with my colleagues, namely LODLAM Patterns (for vocabulary), KRAMA(for data integration and semantic search), and PUNDIT (for semantic annotation).
These cases represent my major interests in vocabulary patterns and tool progress in LODLAM 2013, and my presentation was structured in 7P (Preface, People, Place, Program, Presentation and Proposition). Preface, People, Place and Program are general information about the LODLAM and this event; Presentation and Proposition concern about vocabulary patterns and tool progress through identifying problems and providing suggestions that I have learned from the LODLAM 2013.
Vocabulary Confusion
“We feel we’ve got too many choices. All those vocabularies and metadata schemas confuse us about what to do next. We don’t think our archives should remain in the pre-LOD age. But how are we supposed to make the right decision on which vocabulary to use for LOD-lizing our data?” Major doubts I have heard at Montreal and Taipei reflect the fact that we are not alone in having experienced such confusions. The transformation of a record-based and document-centric metadata structure into a data-centric and link-based web format remains the major challenge both for Library and Web communities.

For the majority of us, the real reason for concern is not the big intellectual constructs of precise models or elaborate vocabularies. Rather, we worry about the library data is short of contextual information; about the weak structure of the Web and the lack of consideration about semantic content during indexing; and about the type of resources and institutional considerations for criteria choices.
These worries brought my consideration in how to share my LODLAM experience with my colleagues. That is, instead of being trapped in some weakness of current problems, focusing more on the strength of LOD may open more positive possibilities. In other words, by activating common languages and international standards, looking for sound tool practices as well as learning from others are the basic approaches to making the LAM stakeholoders move forward to the LOD vision further and faster.
A Common Pattern Helps.
 No one disagrees with that the international standards or common data models are the keys to data sharing and interoperation. Although I did not participate in specific sessions about this issue at Montreal, I first introduced the Europeana Data Model (EDM), which is the core of the Europeana projects (with more than 130 data partners), and which is related to KARMA and PUNDIT to my colleagues as a must-know model. The EDM provides links between Europeana objects, and between an object and its contextual information, while at the same time assists data partners making their metadata visible on the Europeana portal.
No one disagrees with that the international standards or common data models are the keys to data sharing and interoperation. Although I did not participate in specific sessions about this issue at Montreal, I first introduced the Europeana Data Model (EDM), which is the core of the Europeana projects (with more than 130 data partners), and which is related to KARMA and PUNDIT to my colleagues as a must-know model. The EDM provides links between Europeana objects, and between an object and its contextual information, while at the same time assists data partners making their metadata visible on the Europeana portal.
Underlying everything the EDM provides is exemplar of semantic data modelling that: (1) the enrichment for datasets with contextual information such as agent, place, or events; (2) the mechanism (i.e. ORE proxy) that allows different descriptions (views) of a same object to co-exit, and later for the use of provenance. The core data structure is based on Open Archive Object Reuse and Exchange Model (OAI-ORE), which supports the context of different aggregations and referencing resources. However, the later may become the major shortcoming of this model.
Of course, it would be a mistake to presume the process of a new model goes smoothly, or a single model could support all practices efficiently. Critics of the EDM also include (1) the vocabulary is not sufficient or too distinct; (2) problems of imprecise mappings from original metadata (because of the difficulty of managing varieties of metadata vocabularies). As vocabulary and ontology mapping/alignment are key issues in Semantic Web, LAM for LOD certainly needs to face this same challenge without missing a bit.

Nevertheless, alignment/mapping requires deep understanding of each vocabulary. Therefore, a common pattern recognized by domain or cross-domain experts may help. For instance, Ontology Design Patterns (ODP), Linked Data Patterns, or Multilingual Linked Data Patterns (MLOD) are such cases which have been practiced well in Semantic Web and Linked Open Data communities. And that’s what LODLAM Patterns to the cultural heritage resources here for.
LODLAM Patterns is a method that can assist to learn a variety of regularities among categories of linked objects. Personally I find the template is helpful. The seven key issues: Problem, Context, Forces, Solution, Related Patterns, Examples, and References offer the prospect of capturing ideas among different vocabulary designs (particularly helpful from my experience for reconsidering several event ontologies). In other words, cultural heritage resources are the ones we all have in abundance. It may not be in our power to build new vocabularies or models for the new emerging LOD, but it definitely always be an option to give our attention to a pattern that serves LODLAM.
Practice first, Decision later.
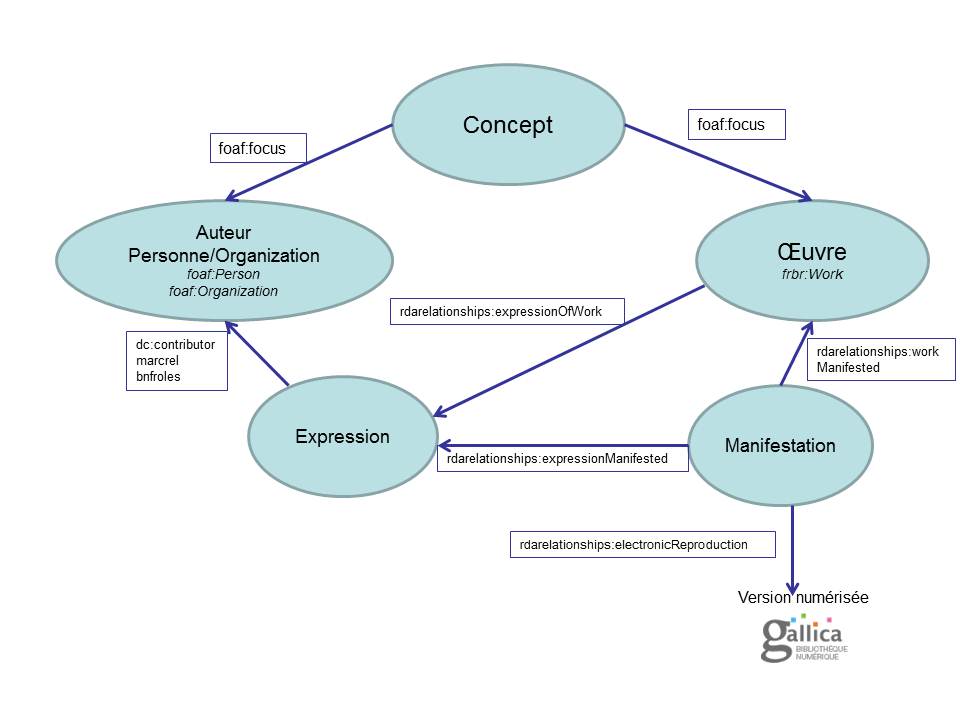
 When we talk about vocabulary confusion we often reach for making decisions between original vocabularies we have used for years and between new emerging ones for LOD. The good news is that we do not need to “upgrade” our whole data at once. Learning from the experience of Europeana, mostly are portions of the data with their own preference, which includes individually preferred data model and metadata schema. For instance, data partners of the Europeana support partial datasets through EDM on the Europeana portal. But the individual institution like Bibliothèque nationale de France (data.bnf.fr) uses FRBR, FRAD and FRSAD models and record identifiers such as ARK identifiers and URIs for their own LOD project. Also quite differently, the British National Bibliography (BNB) Linked Open Data is in favour of Bibliographic Ontology, Bio ontology, British Library Terms, Dublin Core, and Event Ontology, etc. (e.g. data models for book and serials)
When we talk about vocabulary confusion we often reach for making decisions between original vocabularies we have used for years and between new emerging ones for LOD. The good news is that we do not need to “upgrade” our whole data at once. Learning from the experience of Europeana, mostly are portions of the data with their own preference, which includes individually preferred data model and metadata schema. For instance, data partners of the Europeana support partial datasets through EDM on the Europeana portal. But the individual institution like Bibliothèque nationale de France (data.bnf.fr) uses FRBR, FRAD and FRSAD models and record identifiers such as ARK identifiers and URIs for their own LOD project. Also quite differently, the British National Bibliography (BNB) Linked Open Data is in favour of Bibliographic Ontology, Bio ontology, British Library Terms, Dublin Core, and Event Ontology, etc. (e.g. data models for book and serials)
The problem with the conventional process of “decision-plan-practice” approach for the situation of LAM toward LOD is that it rarely works. The quantity, quality and complexity are the major characteristics of LAM data. A big decision making with a complete detail planning for LOD-lizing the LAM data may result in fails. The main reason is that most of us haven’t had any experience of what the task is rely like in LOD clouds. Vocabularies, data models, tools for LOD are still in the process of “evolution”. The experiential learning process both for LAM and LOD community individually and collaboratively is required.
Taking a small step of practical actions step by step is suggested in our discussion session in IIS at my presentation:
 when I was at Montreal.") |
| The building behind is IIS, Taipei Taiwan. An interesting thing is that I found this when I was at Montreal. |
- identifying the priority portion of datasets for possible sharing (data that we believe that are common to the LODLAM and that can be shared most meaningfully);
- practicing data model conversion tools, e.g. OpenRefine or KARMA will offer a numerous choices of vocabulary adjustment functions for data integration and help curators to convert local thesaurus to external vocabularies;
- trying out semantic annotation of web contents. The tool like PUNDIT, which provides annotation approaches for textual comments, semantic tagging, name entities recognition and the use of taxonomies and ontologies, as well as supports RDF statement made by general users, is pretty promising;
- publishing the trial data to LOD to have the experience of meaningful linkages between datasets of different domains, between datasets of the past, present, and unknown future for surprising applications.
- participating more in LODLAM activities to have face-to-face and personal communication and interactions.
Then we will be in a position to make better decisions on how to and what to LOD-lizing the LAM data, with confidence and success.





{kind=link}